
Let’s have a look at our battle plan.
- Part 1: A gentle introduction to outlier detection
- Part 2: Algorithms and implementations
- Part 3: Model deployment in production with Docker and AWS (S3, ECR, SageMaker)
Let’s jump into Part 1: A gentle introduction to outlier detection
Data and AI empower modern business
Data is ubiquitous. Finding one organization or science without data or working without data is impossible. Therefore, a data-driven decision is increasingly essential to boost the performance of any organization, but how can data-based solutions innovate every corner of modern business? The answer is by leveraging Artificial Intelligence methods, i.e. data mining, machine learning and deep learning. This way, stakeholders can understand patterns and insights from past data using a model. Then, they use this model to predict patterns from coming data. For example, Airbnb uses their historical data about rented rooms, such as year, district, area space, number of rooms, facilities, proximity services, price, etc., to predict how much it costs if a new room for rent is coming. Likewise, an e-commerce company like Amazon can use users’ data to predict and recommend items that may fit user tastes.
Understanding the dataset is foremost necessary
A dataset can contain multiple features and multiple samples. The former is referred to as variables, while the latter means the number of observations.
Thanks to the advances in cloud-based storage and data acquisition techniques: weblog, Internet of things sensors, etc., an organization can store and access with ease a vast amount of detailed information, in term of both the number of samples and features.
Within a dataset, each sample can have one or many features. The combined information of all features represents the pattern of that sample. Typically, many samples can share a specific pattern. Therefore, they can be classified into the same class. A dataset can have many classes.
In a real-world application, a dataset can suffer from missing data, duplicated samples, wrong data type, incoherent data values, etc. Dealing with these problems is the first step before building any ML system for prediction, as indeed these data will be feeding algorithms.
What is outlier detection?
In some applications, we assume all data samples within a dataset share the same pattern or, differently said, they are considered to belong to only one class. One question that arises here is whether this assumption is always correct. In a real-world dataset, there are always small samples with different patterns from the expected ones. It means there exist samples that belong to other classes that we don’t know. Such a strange data sample can be defined as an outlier.
“An outlier is an observation which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism” [1]. Obviously the tricky part resides in the definition of “so much”…
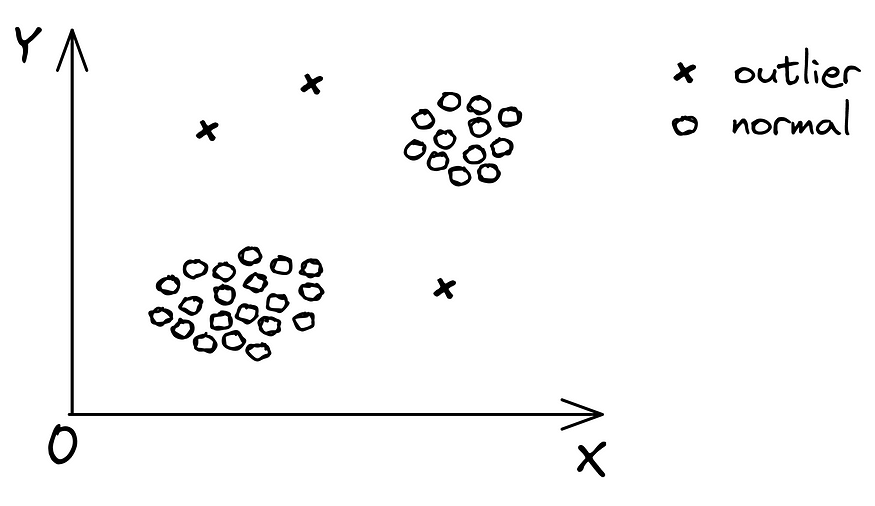
So outlier detection is a technique that aims to detect the outliers. It can be seen as a binary classification problem, in which the outlier and normal samples are assigned to the class label of 1 and 0, respectively.
Outlier detection is helpful in many applications
Transaction-based companies or services can reduce losses due to fraud by leveraging an outlier detection system to predict whether a future transaction is fraudulent based on their previous fraud transaction history.
In medical diagnosis, data derives from numerous medical devices, for example, MRI (Magnetic Resonance Imaging) scans, ECG (Electrocardiogram), etc. Therefore, detecting unusual patterns from those data could indicate a potential health issue, like a tumor.
For IoT applications, data is derived from sensors to detect environmental and geographical information. Unfortunately, the data is highly subject to measurement errors that can cause the final data analysis to deviate and lose pertinence. That’s when outlier detection comes in handy.
Network security is also an essential concern for every organization. Detecting malicious activity in a network system, like unauthorized access, could indicate an intrusion attack on the network.
For traffic surveillance, this technique can help detect abnormal behaviors of drivers, for example, driving in the wrong direction, exceeding the red light at a roundabout, etc.
For the stock price prediction system, anomaly data can affect the trending curve that could produce a wrong price prediction. Therefore, outlier detection is needed to remove outliers before leveraging an ML model for price prediction.
For NLP (Natural Language Processing) applications, outlier detection can be leveraged to detect fake news or negative comments on a product or a film.
In industrial systems like wind turbines or bridges, the devices and their mechanical parts are usually exposed to high loads, extreme temperature and so on. Detecting and repairing early potential damage to the systems via scanned images or other recorded data are very important to prevent accidents and economic losses.

Some of the above applications are illustrated in Figure 2. It can be seen that outlier detection is a vital part of almost all ML ecosystems.
Building an outlier detection system high and robust performance is a challenge
The benefit of outlier detection in the above use-cases is undeniable. However, obtaining a high-performance and robust system of outlier detection is non-trivial. Some of the major factors for this challenge are:
- Different types of outliers, such as local, global, dependency, and clustered outliers, need to be considered in advance. One specific algorithm tends to have better results on one particular type of outlier than others [7].
- Noise and data corruption, such as duplicated outlier, irrelevant features, and annotation errors, are other problems that add complexity when building an outlier detection system [7].
- High dimensionality in a dataset may add more unnecessary attributes that could obscure or even conceal the level of outlier nature [8].
Well, we go to the end of this article.
To summarize, this part has firstly introduced you with the increasingly important role of data and AI in modern business and the importance of dataset understanding before building a ML system. From this context, the outlier detection problem is defined. The article has also provided a quick review of different applications of outlier detection and some significant challenges in building a successful outlier detection system.
In the next part, we will introduce different algorithms for outlier detection and their implementations. See you soon for the next part of this journey.
References
[1] D. M. Hawkins, Identification of outliers. Springer, 1980, vol. 11.
[2] Raghavendra Chalapathy and Sanjay Chawla, Deep Learning for Anomaly Detection: A Survey, 2019 (https://arxiv.org/abs/1901.03407)
[3] Xuemei Xie, Chenye Wang, Shu Chen, Guangming Shi, and Zhifu Zhao. Real-time illegal parking detection system based on deep learning. In Proceedings of the 2017 International Conference on Deep Learning Technologies, pages 23–27. ACM, 2017.
[4] Thomas Schlegl, Philipp Seeb¨ock, Sebastian M Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International Conference on Information Processing in Medical Imaging, pages 146–157. Springer, 2017.
[5] Ahmad Javaid, Quamar Niyaz, Weiqing Sun, and Mansoor Alam. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), pages 21–26. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), 2016.
[6] Mehdi Mohammadi, Ala Al-Fuqaha, Sameh Sorour, and Mohsen Guizani. Deep learning for iot big data and streaming analytics: A survey. arXiv preprint arXiv:1712.04301, 2017.
[7] Songqiao Han and Xiyang Hu and Hailiang Huang and Mingqi Jiang and Yue Zhao, ADBench: Anomaly Detection Benchmark, axXiv, 2022 (https://arxiv.org/abs/2206.09426)
[8] Thudumu, S., Branch, P., Jin, J. et al. A comprehensive survey of anomaly detection techniques for high dimensional big data. J Big Data 7, 42 (2020). https://doi.org/10.1186/s40537-020-00320-x