
Machine Learning and Artificial Intelligence,algorithms, Big Data and data analysis are on the rise.
Every day, more companies are opting to try to obtain information and insights from the data they have stored, or are starting to store. Data that was forgotten in servers without use. Well-calibrated probabilities can help them with this kind of information.
This data allows companies to detect fraud, try new marketing strategies, discover faults in machinery, etc. In general, this data and this information allow companies to try new business approach, maximise their profits and their clients’ satisfaction.
In general, Machine Learning and AI algorithms, especially classification algorithms, produce class predictions for a new object without providing a justified explanation. That is, this person will commit credit card fraud while this other person will not. This truck will have a breakdown while this other truck will not. But the way a decision-maker would act will not be the same all the times.
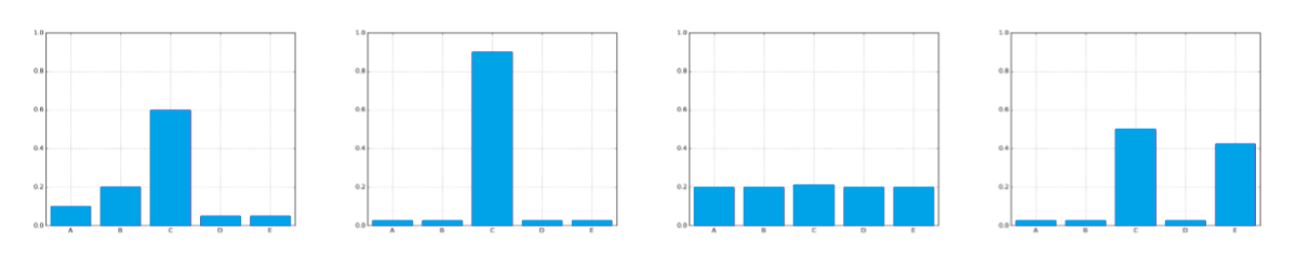
If we take a look at the imagen, the four graphs offer the same class prediction C. Nevertheless, a decision-maker would act wildly different between the second and the third case.The path to take is very clear in the second case while it is not clear at all in the third.
This makes confidence measures necessary. Frequently, this predictions have a probability associated. That is, if we have a binary classification task this person will commit credit card fraud with an 85% probability –or will not commit credit card fraud with a probability of 15%-, this truck will breakdown with a probability of 54% -or will not breakdown with a 46% probability-, etc. In the first case, the algorithm is pretty sure of the outcome.
Meanwhile, in the second case, the model is not really sure. It is slightly more confident that the truck will breakdown tan it will not, but the probabilities are not that far from those of the toss of a coin.
Additionally, the interpretation of these probabilities may be skewed by humans.If we take a closer look at the 2016 US president elections, all polls predicted that Hillary Clinton would win with a, although not much, higher probability than Donald Trump, which did not happen. The probabilities were similar to the probabilities of the truck breakdown in the previous example. Hillary Clinton’s victory was a sure thing for many people, although Donald Trump still had 46% probabilities of winning.
Focusing on more extreme cases such as the credit card fraud, the majority of the people interprets a probability of 85% as a sure thing, when it is not necessarily that way. If there was a fraud with a probability of 85%, then the model should be right in about 85% of the cases and not 100%, as the population generally interprets.
More clearly, the predicted behaviour of the model and the actual behaviour must match or be very similar.
Methods that help producing well-calibrated probabilities
A prediction with 60% of probability must be right in 60% of the cases. These are called well calibrated probabilities. There are several older methods that help producing well-calibrated probabilities such as Platt Scaling and Isotonic Regression. There are also new methods such as Conformal Prediction and Venn Prediction, which belong to the same family.
In conclusion, with Machine Learning algorithms, obtaining the highest accuracy should not be the only aim, but also to have well-calibrated probabilities, as the results then may not reflect the actual behaviour expected of the model by its users.